# 【基于随机森林算法的分类预测】附详细Matlab代码 |
您所在的位置:网站首页 › matlab 多分类预测 › # 【基于随机森林算法的分类预测】附详细Matlab代码 |
# 【基于随机森林算法的分类预测】附详细Matlab代码
|
文章目录
1. 引言2. 随机森林算法原理2.1 决策树基础2.2 随机森林的构建
3. 随机森林分类的实现3.1 数据准备3.2 模型训练3.3 模型预测
4. 模型评估5. 参数调优6. 结论7. 参考文献
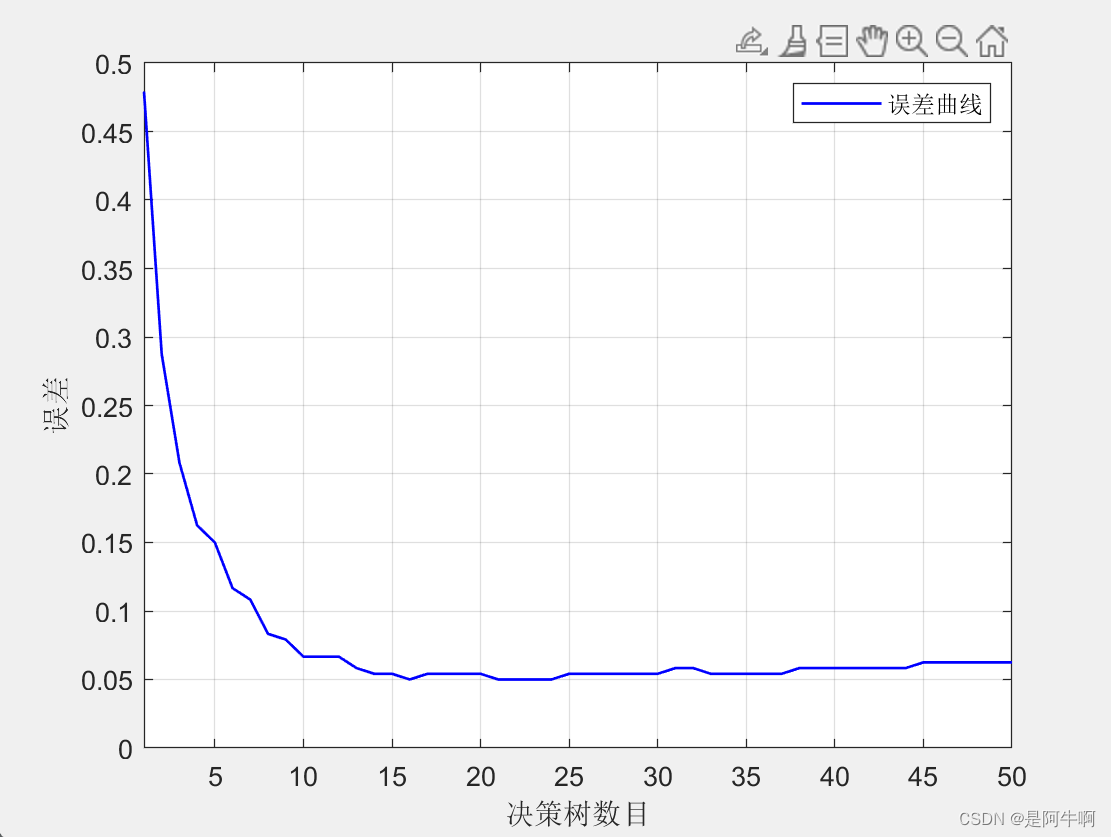
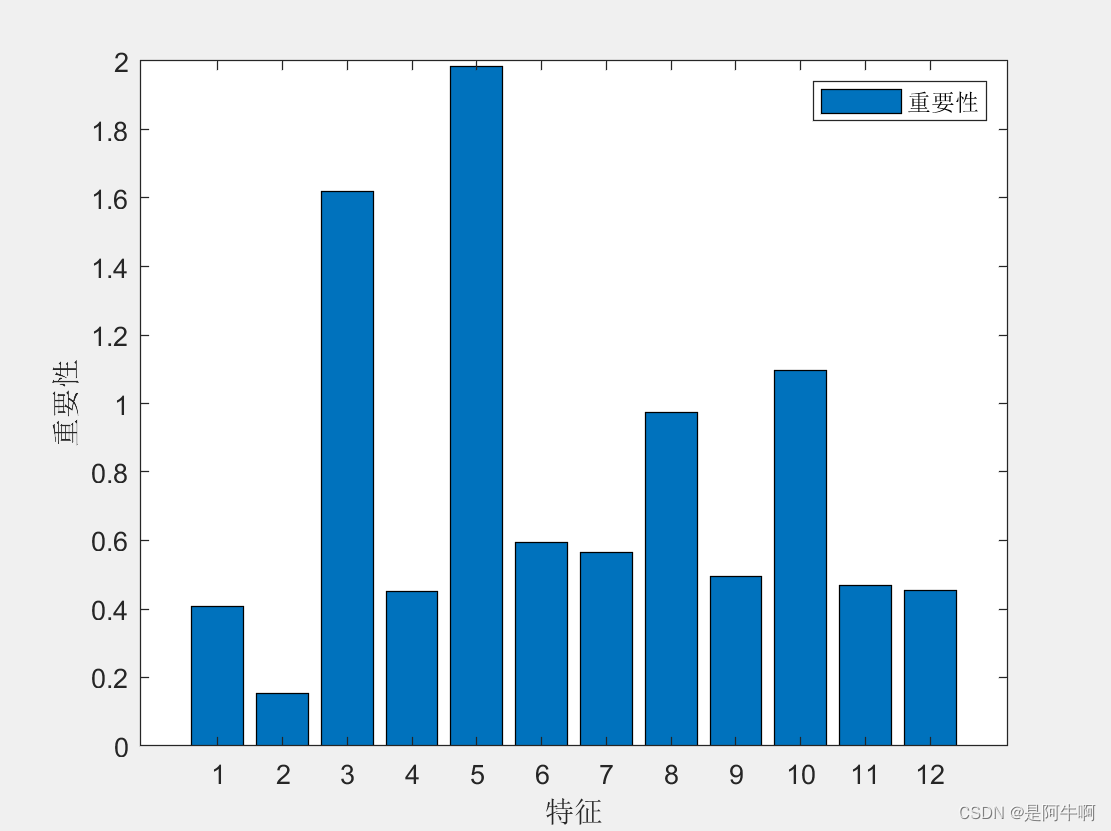
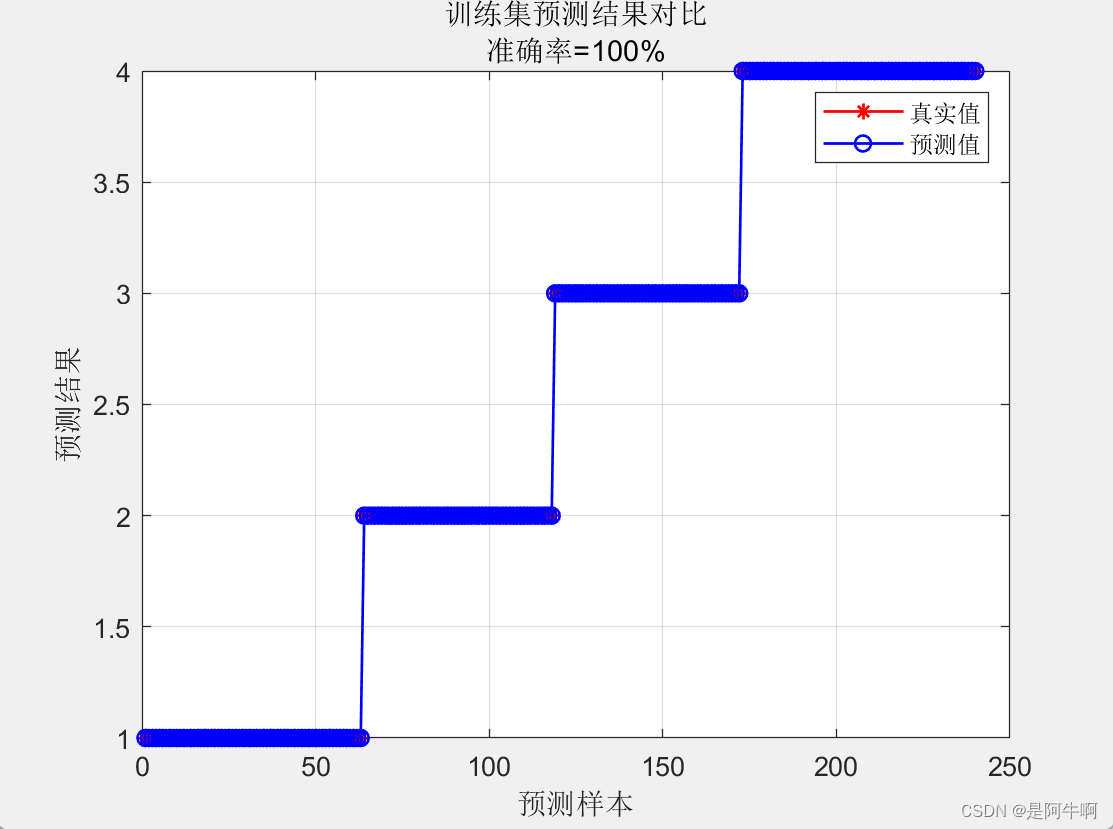
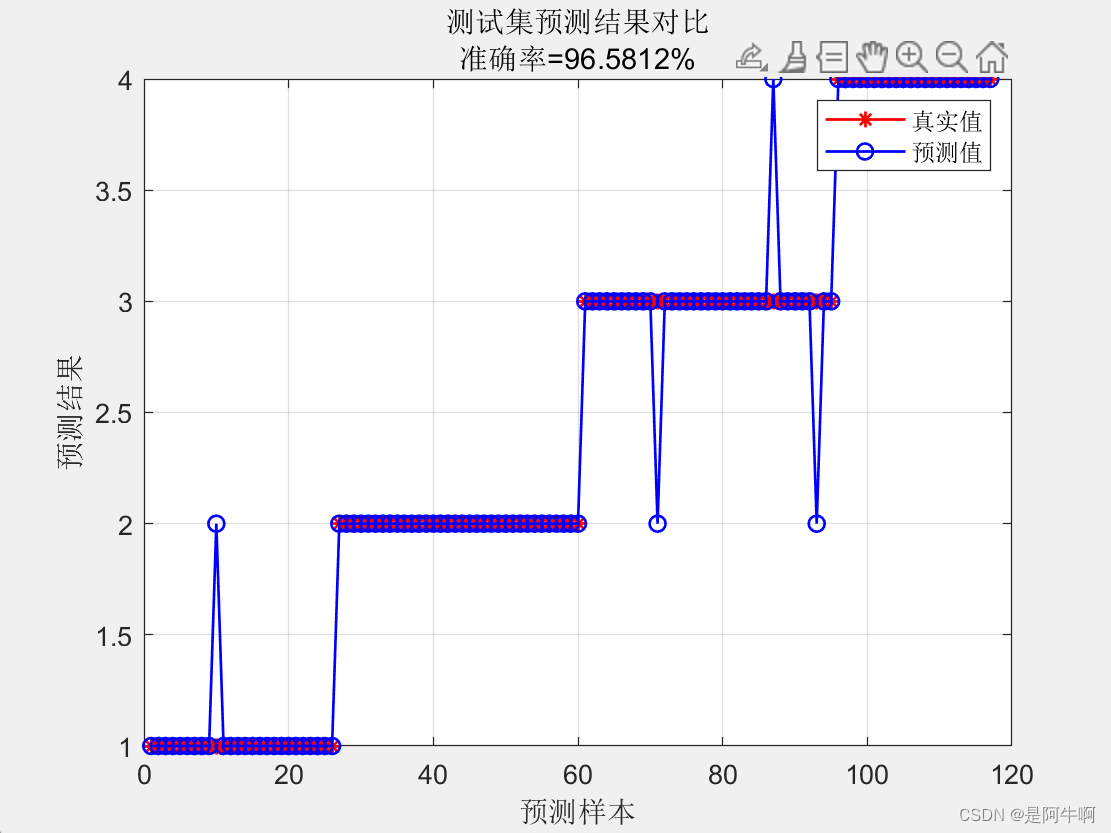
在机器学习的众多算法中,随机森林因其出色的性能和易于理解的特点而广受欢迎。特别是在分类问题中,随机森林算法能够提供高准确率的预测,同时还能有效地处理高维度和非线性数据。本文将详细介绍如何使用随机森林算法进行数据分类预测,包括算法原理、实现步骤、模型评估以及参数调优。文中详细代码请见:https://www.kdocs.cn/l/cmQ0BXiurpbg 随机森林是一种集成学习方法,它通过构建多个决策树并结合它们的预测结果来提高整体的预测性能。在分类问题中,随机森林通过投票机制来决定最终的分类结果,即多数决策树的分类结果将被采纳。这种方法不仅减少了过拟合的风险,而且提高了模型的泛化能力。 2. 随机森林算法原理 2.1 决策树基础决策树是一种基本的机器学习方法,用于分类和回归。它通过一系列的决策节点来预测目标变量的类别。在分类树中,每个叶节点代表一个类别,该类别是该节点所有训练样本中出现次数最多的类别。 2.2 随机森林的构建随机森林通过以下步骤构建: Bootstrap采样:从原始数据集中随机抽取多个子集(bootstrap样本)。决策树构建:对每个bootstrap样本构建一个决策树,但在每个节点上,只考虑特征的一个随机子集来决定最佳分割。预测:对于分类问题,每个树的预测值是叶节点上类别的多数投票结果。集成预测:所有树的预测值进行投票,得到最终的分类结果。 3. 随机森林分类的实现 3.1 数据准备在开始之前,我们需要准备数据。数据应该包括特征和目标变量。以下是一个简单的数据准备示例: # 这里假设你已经有一个数据集,名为dataSet ,包含特征和目标变量 %% 导入数据 dataSet = xlsread('dataSet.xlsx'); 3.2 模型训练接下来,我们将使用随机森林分类模型进行训练。这里我们使用matlab库中的TreeBagger。 %% 训练模型 treeCount = 50; % 决策树数目 minLeafSize = 1; % 最小叶子数 OOBPrediction = 'on'; % 打开误差图 OOBPredictorImportance = 'on'; % 计算特征重要性 Method = 'classification'; % 分类还是回归 model = TreeBagger(treeCount, normalizedFeaturesTrain, normalizedLabelsTrain, 'OOBPredictorImportance', OOBPredictorImportance, ... 'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', minLeafSize); featureImportance = model.OOBPermutedPredictorDeltaError; % 重要性 3.3 模型预测训练完成后,我们可以使用模型进行预测。 # 假设normalizedFeaturesTest是测试集的特征数据 %% 模型测试 predictionsTrain = predict(model, normalizedFeaturesTrain); predictionsTest = predict(model, normalizedFeaturesTest); 4. 模型评估为了评估模型的性能,我们需要使用适当的评估指标。对于分类问题,常用的指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)。 # 计算准确率 %% 性能评价 accuracyTrain = sum((predictionsTrain' == labelsTrain)) / trainSize * 100; accuracyTest = sum((predictionsTest' == labelsTest)) / testSize * 100;
随机森林模型包含多个参数,如n_estimators、max_depth、min_samples_split等,这些参数可以通过交叉验证进行调优。 from sklearn.model_selection import GridSearchCV # 定义参数范围 param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [None, 10, 20], 'min_samples_split': [2, 5, 10] } # 使用GridSearchCV进行参数调优 grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy') grid_search.fit(X, y) # 输出最佳参数 print(grid_search.best_params_) 6. 结论随机森林分类模型是一种强大的预测工具,它通过集成多个决策树来提高预测的准确性和稳定性。通过适当的数据准备、模型训练、评估和参数调优,我们可以构建一个高效的随机森林分类模型。 7. 参考文献 Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32.Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.通过本文的介绍,希望读者能够理解并掌握随机森林分类模型的基本原理和应用方法,从而在实际问题中有效地应用这一强大的工具。 |

【本文地址】
今日新闻 |
推荐新闻 |